When running Azure Pipelines there are valid reasons why you might want to host agents yourself instead of using the Microsof-hosted agents. With self-hosted agents you have full control over installed tools as well as resources and performance and therefore infrastructure costs. Caching files between pipeline runs is easier and costs per self-hosted parallel job are only half the costs of Microsoft-hosted jobs (not including infrastructure costs).
While you could just set up a self-hosted agent on any machine you might want a more dynamic approach where the number of Azure Pipeline agents automatically scales with the number of pipeline jobs that need to be run. The available Azure Virtual Machine Scale Set agents are not very dynamic and the startup and shutdown takes very long.
If you already have a container infrastructure you should instead run your self-hosted agents within containers. Not only the startup of agents is a lot faster but you also get an always clean and easy to set up environment that can be easily scaled. If you’re using Kubernetes to run your containers, KEDA is your best friend for autoscaling your self-hosted agent containers.
TL;DR
- Create a PAT with Agent Pools (read, manage) scope in your Azure DevOps organization and store the information into a secret:
kubectl create secret generic pipeline-auth --from-literal=AZP_URL=https://dev.azure.com/YourOrg --from-literal=AZP_TOKEN=YourPAT - The Azure Pipeline needs at least one agent in the pool to not fail instantly with No agent found when we scale to zero. For that we register a single dummy build agent in the pool and shut it down afterwards:
kubectl apply -f https://raw.githubusercontent.com/lippertmarkus/keda-azure-pipelines-agent/main/kubernetes/job-setup.yml - Install KEDA:
helm repo add kedacore https://kedacore.github.io/charts helm repo update helm install keda kedacore/keda --namespace keda --create-namespace - Now we add the
ScaledJobresource for KEDA to watch the Azure Pipelines agent pool job queue and start agents dynamically:kubectl apply -f https://raw.githubusercontent.com/lippertmarkus/keda-azure-pipelines-agent/main/kubernetes/scaledjob.yml - Watch how KEDA automatically creates one Kubernetes
Jobfor each Azure Pipeline job in the queue. The agents register themselves, run the jobs and unregister themselves:
If you want to know how all of this works in detail, read on!
Setting up a pipeline in Azure DevOps
If you not already have, set up an organization, a project and a repository with a README.
Now use Pipelines ➡️ New Pipeline to create a new pipeline, choose Azure Repos Git as the source as well as the repository you just created. You can use the starter pipeline as a base and replace the YAML with the following minimal pipeline:
trigger:
- main
pool: Default
steps:
- script: echo Hello, world!
By specifying the pool name instead of pool.vmImage like the starter pipeline does we can make sure to use self-hosted agents instead of Microsoft-hosted agents.
To allow our self-hosted agents to register themselves we also create a PAT with the Agent Pools (read, manage) scope in our Azure DevOps organization and store the information to a secret:
kubectl create secret generic pipeline-auth --from-literal=AZP_URL=https://dev.azure.com/YourOrg --from-literal=AZP_TOKEN=YourPAT
With that we are able to run containerized build agents.
Containerized build agents and scaling to zero
The Azure DevOps docs describe how you can create a container image for a containerized build agent.
To allow us to scale the number of agents to zero, we need to modify the startup script in step 5 a bit. The reason behind this is that Azure DevOps needs at least one agent registered inside an agent pool for pipeline jobs to wait for an available agent and not fail immediately with and error like No agent found in pool Default which satisfies the specified demand. To accomplish that we modify the script to allow a dummy agent to register and then shutting itself down without running. The changes are described in the KEDA docs. I added four more lines to immediately shut down the dummy agent after configuring it and not only after the first run. The changes then look like the following:
...
- print_header "4. Running Azure Pipelines agent..."
-
- trap 'cleanup; exit 0' EXIT
- trap 'cleanup; exit 130' INT
- trap 'cleanup; exit 143' TERM
-
- chmod +x ./run-docker.sh
-
- # To be aware of TERM and INT signals call run.sh
- # Running it with the --once flag at the end will shut down the agent after the build is executed
- ./run-docker.sh "$@" & wait $!
+ print_header "4. Running Azure Pipelines agent..."
+
+ if ! grep -q "template" <<< "$AZP_AGENT_NAME"; then
+ echo "Cleanup Traps Enabled"
+
+ trap 'cleanup; exit 0' EXIT
+ trap 'cleanup; exit 130' INT
+ trap 'cleanup; exit 143' TERM
+ else
+ # directly exit the template agent after configuration
+ trap - EXIT
+ exit 0
+ fi
+
+ chmod +x ./run-docker.sh
+
+ # To be aware of TERM and INT signals call run.sh
+ # Running it with the --once flag at the end will shut down the agent after the build is executed
+ ./run-docker.sh "$@" --once & wait $!
With those changes all agents containing template in the name are considered as dummy agents. For those dummy agents we exit after configuring but before running the Azure Pipelines agent and also skip the cleanup logic which would unregister the dummy agent from the agent pool again.
Non-dummy agents are run with the --once flag so each agent runs only one pipeline job and then shuts down automatically instead of running all the time. The container image can be found at lippertmarkus/azure-pipelines-agent:latest along with the sources on GitHub.
Let’s run the following Kubernetes Job to set up the dummy agent:
kubectl apply -f https://raw.githubusercontent.com/lippertmarkus/keda-azure-pipelines-agent/main/kubernetes/job-setup.yml
apiVersion: batch/v1
kind: Job
metadata:
name: azure-pipelines-one-time-setup
spec:
template:
spec:
restartPolicy: Never
containers:
- name: azure-pipelines-agent
image: lippertmarkus/azure-pipelines-agent:latest
env:
- name: AZP_AGENT_NAME
value: setup-template # needs to include "template"
envFrom:
- secretRef:
name: pipeline-auth # reference the secret we created before
With the pipelines agent container image and the dummy agent in place we can now start using KEDA for autoscaling our agents.
Setup autoscaling pipeline agents with KEDA
KEDA is a Kubernetes-based Event Driven Autoscaler. It allows to automatically scale the replicas of Deployments, StatefulSets and other resources based on the number of events needing to be processed. KEDA can also dynamically create Jobs for incoming events. Before going into more detail on how KEDA works, let us first install it:
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
helm install keda kedacore/keda --namespace keda --create-namespace
KEDA provides ScaledObject and ScaledJob resources that define the target resource that should be scaled as well as one or multiple triggers which are providing metrics for the automatic scaling. There are a lot of Scalers which implement those triggers for many different message queues and systems.
For Azure Pipeline agents it makes sense to use the ScaledJob resource as we want to create one Kubernetes Job per incoming event. Kubernetes Job are meant for scenarios where you need to run something to completion, just like we run our agent to execute one pipeline job and then exit. The resource looks like that:
apiVersion: keda.sh/v1alpha1
kind: ScaledJob
metadata:
name: azure-pipelines-scaledjob
spec:
jobTargetRef:
template:
spec:
restartPolicy: Never
containers:
- name: azure-pipelines-agent
image: lippertmarkus/azure-pipelines-agent:latest
envFrom:
- secretRef:
name: pipeline-auth
triggers:
- type: azure-pipelines
metadata:
poolName: "Default"
organizationURLFromEnv: "AZP_URL"
personalAccessTokenFromEnv: "AZP_TOKEN"
pollingInterval: 10
successfulJobsHistoryLimit: 5
failedJobsHistoryLimit: 5
maxReplicaCount: 30
rollout:
strategy: gradual # if ScaledJob changes, don't terminate currently running jobs
You can find all details on the ScaledJob resource in the docs, let’s go over some of the interesting parts.
In the jobTargetRef we have defined the Job that should be created similar to the one-time-setup before. The Job references the pipeline-auth secret we created earlier which contains the AZP_URL and AZP_TOKEN variables.
In the triggers we use the Azure Pipelines trigger to watch the Azure DevOps agent pool Default every 10 s (pollingInterval) for new jobs in the queue. To access the Azure DevOps API the trigger uses the credentials in the environment variables of the jobTargetRef that are sourced from the pipeline-auth secret. The organizationURLFromEnv and personalAccessTokenFromEnv specify from which environment variables those credentials are retrieved from.
We also set successfulJobsHistoryLimit and failedJobsHistoryLimit to reduce the number of finished jobs to keep history of and limited the maximum replicas of agents to 30 by maxReplicaCount. Lastly you also want to set the rollout strategy to gradual so KEDA doesn’t remove running jobs when you change the ScaledJob object but only considers the changes for newly created ones.
With that let’s try out our setup.
Azure Pipelines agent autoscaling in action
We want to run a pipeline and verify the autoscaling in action. First go back to your Azure DevOps project and to Project Settings ➡️ Agent pools ➡️ Default ➡️ Agents. Here you should see the offline setup-template dummy agent we set up before. In a terminal run watch -n 1 kubectl get pod to watch the pipeline agent pods that will be automatically created.
Now in a second browser window go to Pipelines ➡️ YourPipeline ➡️ Run pipeline, click on Run and watch what happens:
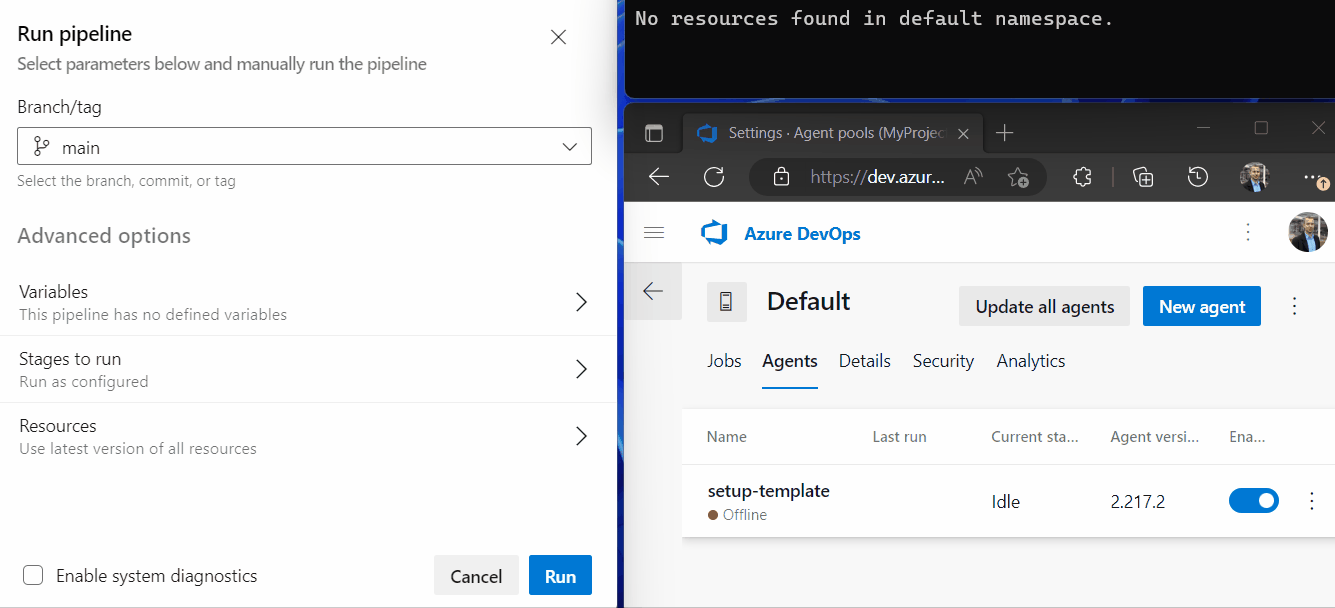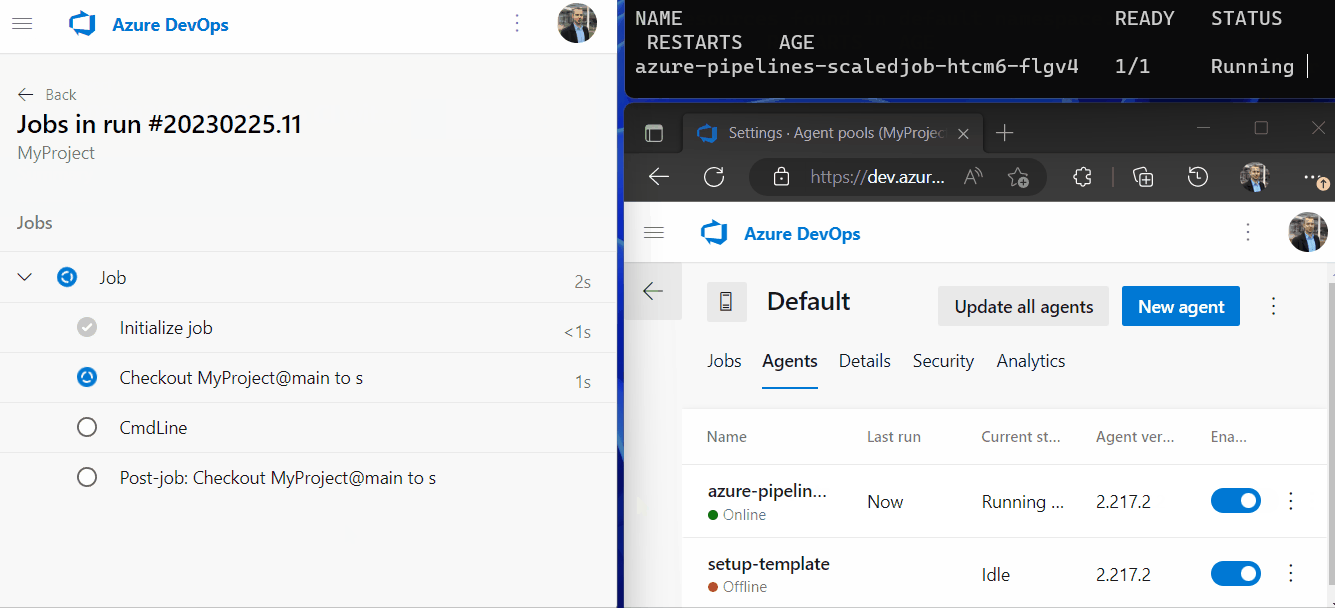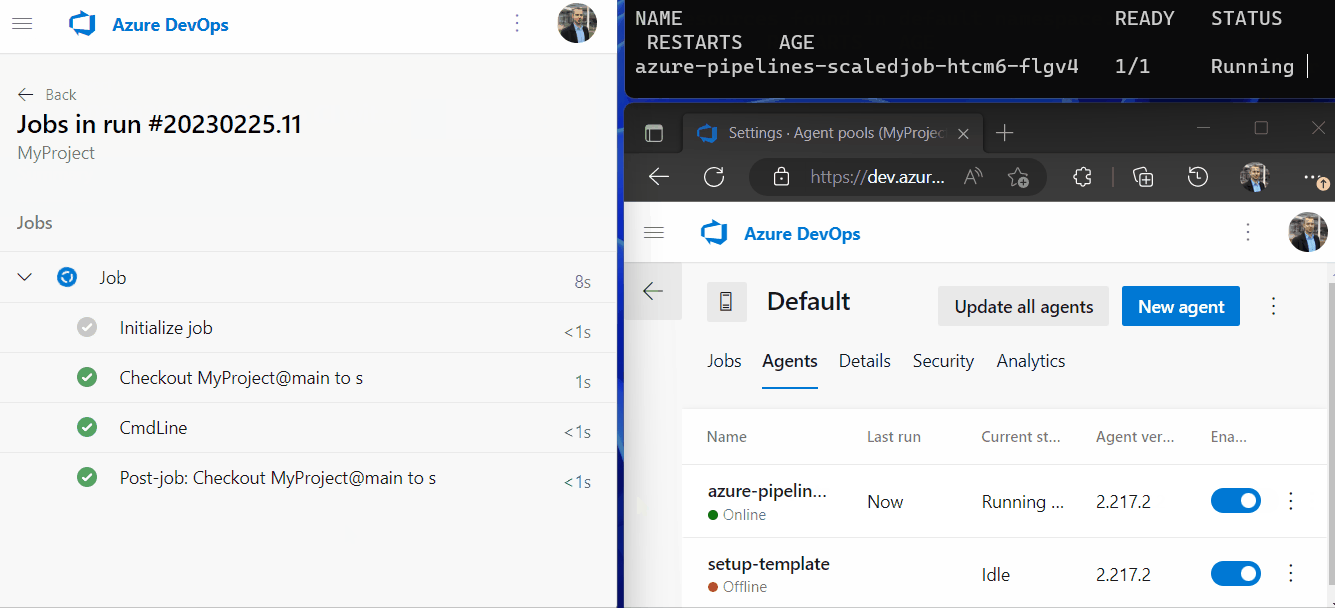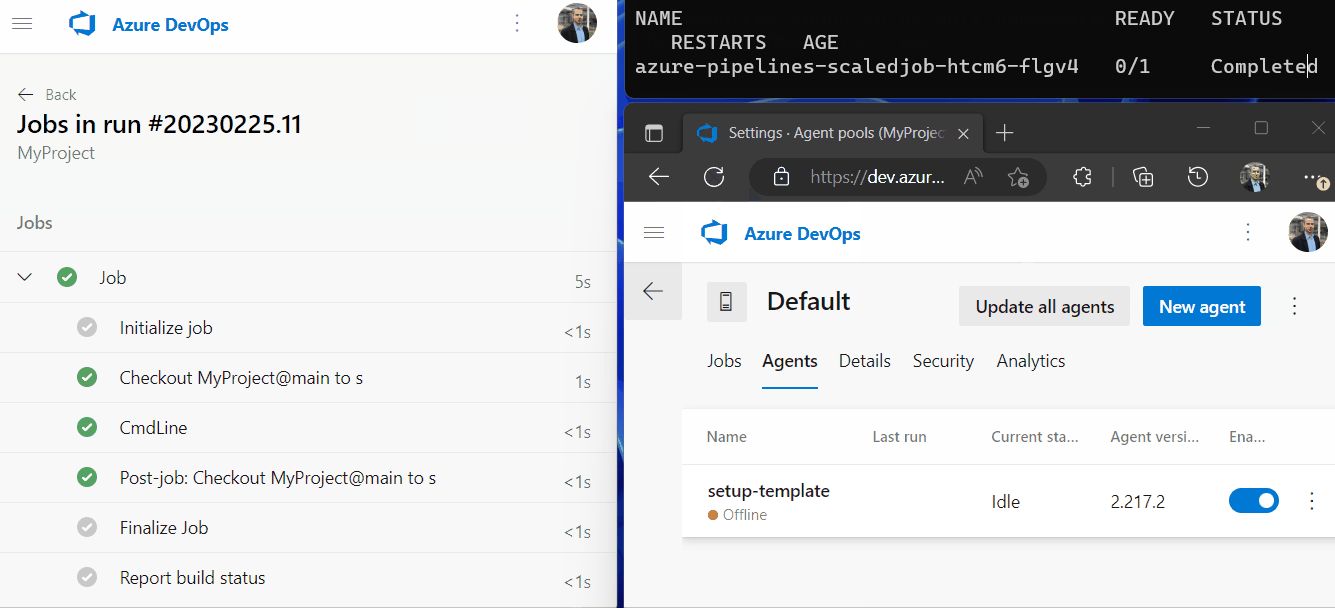
After clicking Run a new Azure Pipeline job was added to the queue of the Default agent pool. Due to our trigger in the ScaledJob object KEDA finds the pending pipeline job in the queue and creates a new Kubernetes Job for it. The newly created agent pod pops up in the terminal and after registration in the agent pool and startup it’s also visible as online in the Agents tab of the agent pool.
The new pipeline agent picks up the pipeline job and runs all steps. After the job is executed, the pipeline agent stops due to the --once flag we added and is unregistering itself from the agent pool again. The pod is now in Completed state.
If you have more than one parallel job available in Azure DevOps you can also run multiple jobs in at once and watch KEDA creating multiple agent pods simultaneously. As KEDA scales to zero we don’t waste any resources when no pipeline jobs are pending. That’s autoscaling at its best!
There’s more
We had a look at the basic setup for autoscaling containerized Azure Pipelines agents with KEDA. For more advanced setups you might want to think about other aspects as well:
-
If you have pipeline jobs that require different toolsets then you might want to specify
demandsin theazure-pipelinestrigger. This way the autoscaling only triggers when the demands of the pending pipeline job you specified in your pipeline are a subset of thedemandsin the trigger. Those demands also need to be part of the environment variables of theJobinjobTargetRef. Example: You have one pipeline for .NET and another one for Node.js applications that are using the same agent pool. The first pipeline is specifyingdotnetand the second onenodejsas a demand. You create twoScaledJobobjects. The one for .NET hasdemands: dotnetas well as an environment variabledotnet=truein theJob. The otherScaledJobhasdemands: nodejsand the environment variablenodejs=true. EachScaledJobwould use a different agent image with the specific tools installed. -
If you have many different or changing Azure DevOps projects or agent pools then doing the one-time setup of the dummy agent for all of them might be a tedious and time consuming manual work. To automate that you might could use a serverless job within your pipeline that uses the Azure DevOps APIs to register the dummy agent if it doesn’t exist instead of spinning up a real agent that only registers itself and then shuts down. I will look at that in the future and will update here.
Comments